Lecture 05
Fitting Neurons with Gradient Descent
Lecture Overview
- Online, batch, and minibatch mode
- Relation between percetron and linear regression
- An iterative training algorithm for linear regression
- Calculus Refresher I: Derivatives
- Calculus Refresher II: Gradients
- Understanding gradient descent
- Training an adaptive linear neuron (Adaline)
1. Online, batch, and minibatch mode
Perceptron Recap
Let $\mathcal{D} = (\langle \mathbf{x}^{[1]}, y^{[1]} \rangle, \langle \mathbf{x}^{[2]}, y^{[2]} \rangle, \dots, \langle \mathbf{x}^{[n]}, y^{[n]} \rangle) \in (\mathbb{R}^{m} \times {0,1})^{n} $.
- Initialize \(\mathbf{w} := \mathbf{0} \in \mathbb{R}^{m}, \quad b := 0\)
-
For every training epoch:
A. For every \(\langle \mathbf{x}^{[i]}, y^{[i]} \rangle \in \mathcal{D}\):
-
(a) Compute output (prediction) \(\hat{y}^{[i]} := \sigma\bigl( (\mathbf{x}^{[i]})^{\top} \mathbf{w} + b \bigr)\)
-
(b) Calculate error \(\hat{y}^{[i]} := \sigma\bigl( (\mathbf{x}^{[i]})^{\top} \mathbf{w} + b \bigr)\)
-
(c) Update parameters \(\mathbf{w} := \mathbf{w} + \mathrm{err} \times \mathbf{x}^{[i]}, \quad b := b + \mathrm{err}\)
-
“On-line” mode (= SGD: Stochastic Gradient Descent)
- Initialize $ \mathbf{w} := \mathbf{0} \in \mathbb{R}^{m}, \quad b := 0 $
-
For every training epoch:
A. For every $ \langle x^{[i]}, y^{[i]} \rangle \in \mathcal{D} $:
- (a) Compute output (prediction)
- (b) Calculate error
- (c) Update $ \mathbf{w}, \mathbf{b}$
- For step 2, we usually shuffle the dataset prior to each epoch to prevent cycles
- Applies to all common neuron models and (deep) neural network architectures
“On-line” mode II (alternative)
- Initialize $ \mathbf{w} := \mathbf{0} \in \mathbb{R}^{m}, \quad b := 0 $
-
For every training epoch:
A. Pick random $ \langle x^{[i]}, y^{[i]} \rangle \in \mathcal{D} $:
- (a) Compute output (prediction)
- (b) Calculate error
- (c) Update $ \mathbf{w}, \mathbf{b}$
- No shuffling required
Batch mode
- Initialize $ \mathbf{w} := \mathbf{0} \in \mathbb{R}^{m}, \quad b := 0 $
-
For every training epoch:
A. Take all training examples from $\mathcal{D} $:
- (a) Compute output (prediction)
- (b) Calculate error
B. Update $ \mathbf{w}, \mathbf{b}$
Minibatch mode (mix between on-line and batch)
- Initialize $ \mathbf{w} := \mathbf{0} \in \mathbb{R}^{m}, \quad b := 0 $
-
For every training epoch:
A. For every minibatch of size k, namely
$ (\langle x^{[i]}, y^{[i]} \rangle, \dots, \langle x^{[i+k]}, y^{[i+k]} \rangle) \in \mathcal{D}$
- (a) Compute output (prediction)
- (b) Calculate error
- (c) Update $ \mathbf{w} := \mathbf{w} + \Delta \mathbf{w}, \quad \mathbf{b} := \mathbf{b} + \Delta \mathbf{b} $
- This is the most common mode in deep learning because:
- choosing a subset instead of one example at a time takes advantage of vectorization (faster iteration through epoch than on-line)
- having fewer updates than “on-line” makes updates less noisy.
- makes more updates / epoch than “batch” and is thus faster
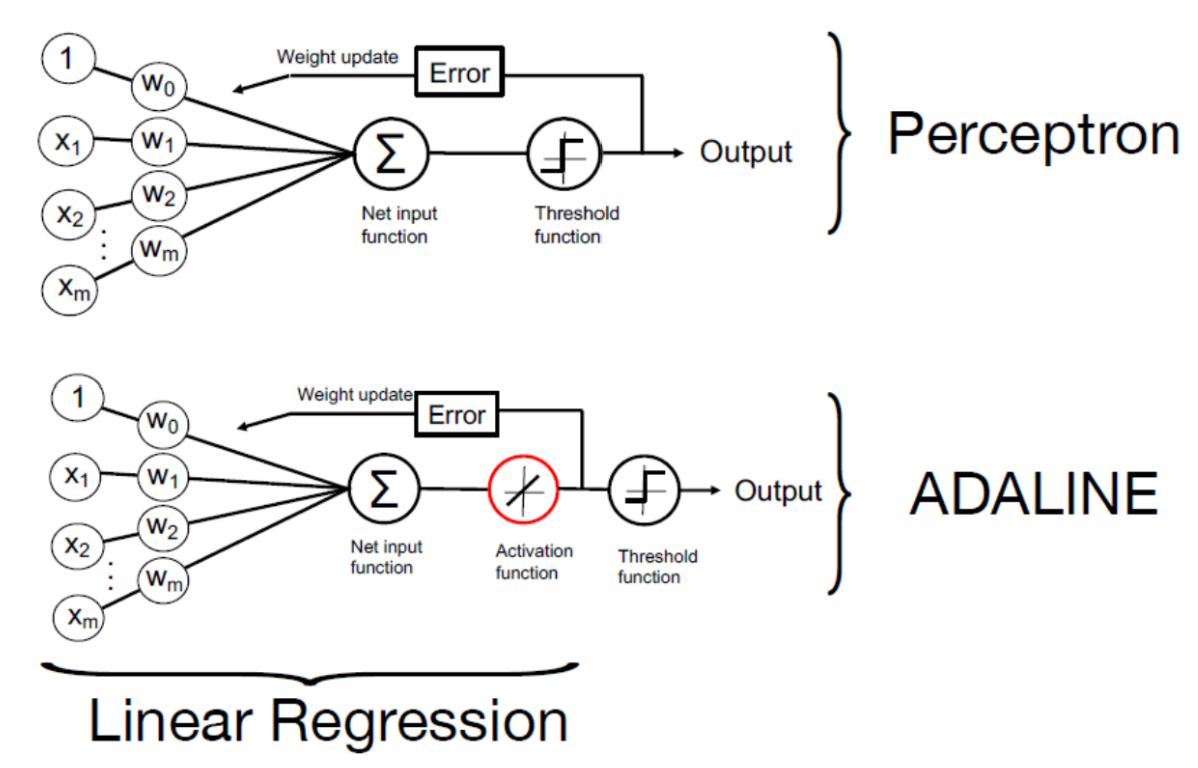
2. Relation between perceptron and linear regression
Perceptron
- activation function is the threshold function
- output is a binary label $\hat{y} \in {0,1}$
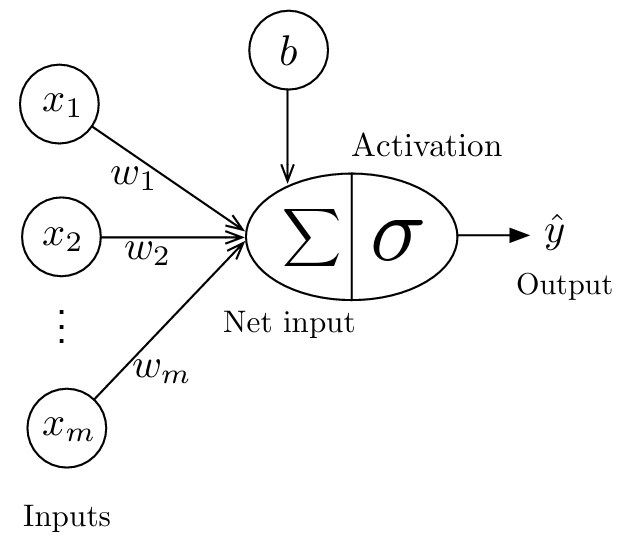
Linear Regression
- activation function is the identity function $ \sigma(x) = x $
- output is a real number $\hat{y} \in \mathbb{R}$
- you can think of linear regression as a linear neuron
(Least-Squares) Linear Regression
, assuming the bias is included in $ \mathbf{w}$, and the design matrix has an additional vector of 1’s
- Generally, this is the best approach for linear regression
3. An iterative training algorithm for linear regression
(Least-Squares) Linear Regression
- A very naive way to fit a linear regression model (and any neural net) is to start with initializing the parameters to 0’s or small random values
- Then, for k rounds
- Choose another random set of weights
- If the model performs better, keep those weights
- If the model performs worse, discard the weights
- Guaranteed to find the optimal solution for very large k, but it would be terribly slow
Better way
- analyze what effect a change of a parameter has on the predictive performance (loss) of a model
- then change the weight a little in the direction that improves the performance (minimizes the loss) the most
- do this in several (small) steps until the loss does not further decrease
Update Rules (“on-line” mode)
Perceptron Learning Rule
- Initialize $ \mathbf{w} := \mathbf{0} \in \mathbb{R}^{m}, \quad b := 0 $
-
For every training epoch:
A. For every $ \langle x^{[i]}, y^{[i]} \rangle \in \mathcal{D} $:
- (a) $ \hat{y}^{[i]} := \sigma\bigl(x^{[i]\top}\mathbf{w} + b\bigr) $
- (b) $ err := \bigl(y^{[i]} - \hat{y}^{[i]}\bigr) $
- (c) $ \mathbf{w} := \mathbf{w} + err \times x^{[i]}, \quad b := b + err $
Stochastic Gradient Descent (Vectorized)
-
Initialize $ \mathbf{w} := \mathbf{0} \in \mathbb{R}^{m}, \quad b := 0 $
-
For every training epoch:
A. For every $ \langle x^{[i]}, y^{[i]} \rangle \in \mathcal{D} $:
-
(a) $ \hat{y}^{[i]} := \sigma\bigl(x^{[i]\top}\mathbf{w} + b\bigr) $
-
(b) $ \nabla{\mathbf{w}}\mathcal{L} = \bigl(y^{[i]} - \hat{y}^{[i]}\bigr)x^{[i]}, \quad \nabla{b}\mathcal{L} = \bigl(y^{[i]} - \hat{y}^{[i]}\bigr) $
-
(c) $ \mathbf{w} := \mathbf{w} + \eta \times \bigl(-\nabla{\mathbf{w}}\mathcal{L}\bigr), \quad b := b + \eta \times \bigl(-\nabla{b}\mathcal{L}\bigr) $
where $\eta$ = learning rate, $\bigl(-\nabla_{\mathbf{w}}\mathcal{L}\bigr)$ = negative gradient
-
Stochastic Gradient Descent (For understanding only)
-
Initialize $ \mathbf{w} := \mathbf{0} \in \mathbb{R}^{m}, \quad b := 0 $
-
For every training epoch:
A. For every $ \langle x^{[i]}, y^{[i]} \rangle \in \mathcal{D} $:
- (a) $ \hat{y}^{[i]} := \sigma\bigl(x^{[i]\top}\mathbf{w} + b\bigr) $
B. For weight $ \boldsymbol{j \in {1, \ldots, m}} $:
-
(b) $ \frac{\partial \mathcal{L}}{\partial w{j}} = \bigl(y^{[i]} - \hat{y}^{[i]}\bigr)x{j}^{[i]} $
-
(c) $ w{j} := w{j} + \eta \times \Bigl(-\frac{\partial \mathcal{L}}{\partial w_{j}}\Bigr) $
C. $ \frac{\partial \mathcal{L}}{\partial b} = \bigl(y^{[i]} - \hat{y}^{[i]}\bigr) $, $ b := b + \eta \times \Bigl(-\frac{\partial \mathcal{L}}{\partial b}\Bigr) $
where $\eta \times \Bigl(-\frac{\partial \mathcal{L}}{\partial b}\Bigr)$ coincidentally appears almost to be the same as the perceptron rule, except that the prediction is a real number, and we have a learning rate
This learning rule is called Gradient Descent
4. Calculus Refresher I: Derivatives
Differential Calculus Refresher
- The derivative of a function $f(x)$ at a point $x=a$ is defined as the limit of the difference quotient (if it exists):
- $\Delta x$ represents an increment in x
- If a function $f(x)$ is differentiable at every point of an interval A, we say that $f(x)$ is differentiable on A. In this case, for each $ x=a \in A$ there exists a derivative $f’(a)$ corresponding to it.
- This defines a new function on $A$, namely the derivative function $ f’(x)$
-
Examples
-
$ f(x)=2x$:
- $ f(x)=x^2$:
Cheatsheet 1: Frequently used derivative formulas
Cheatsheet 2: Derivative Rules
- Sum Rule
- Difference Rule
- Product Rule
- Quotient Rule
- Reciprocal Rule
- Chain Rule
- The chain rule is the essence of training neural networks.
Chain Rule & Computation Graph
- For a nested function $ F(x)=f(g(x))=z$
- Its computational graph:
- Derivative of the nested function: $F’(x)=f’(g(x))g’(x)=z’$
- Computational graph of derivative function:
- Pytorch keeps computational graphs in the background and computes the derivatives of most differentiable functions automatically.
Chain Rule & Leibniz Notation
- For efficiency, we use the Leibniz notation:
- this is useful when writing long function compositions:
- Here’s an example of implementing the Chain Rule (using Leibniz notation):
- $f(x)=\log(\sqrt{x})$:
- reverse mode and forward mode:
- notice that:
- Backpropagation is basically “reverse mode” auto-differentiation. It is cheaper than forward mode if we work with gradients because we would have matrix-vector multiplications instead of matrix-matrix multiplications.
5. Calculus Refresher II: Gradients
Derivatives of Multivariable Functions
- For a multivariable function $f(x_1,x_2,x_3,…x_m)$:
- Example:
- $f(x,y)=x^2y+y$
Multivariable Chain Rule
- Example:
- $f(g,h)=g^2h+h$, where $g(x)=3x$ and $h(x)=x^2$
Multivariable Chain Rule in vector form
- define:
- and:
- we also have:
- Putting it together:
The Jacobian Matrix
- The i-th row of the Jacobian matrix is the gradient vector of $f_i$:
6. Understanding Gradient Descent
Back to Linear Regression
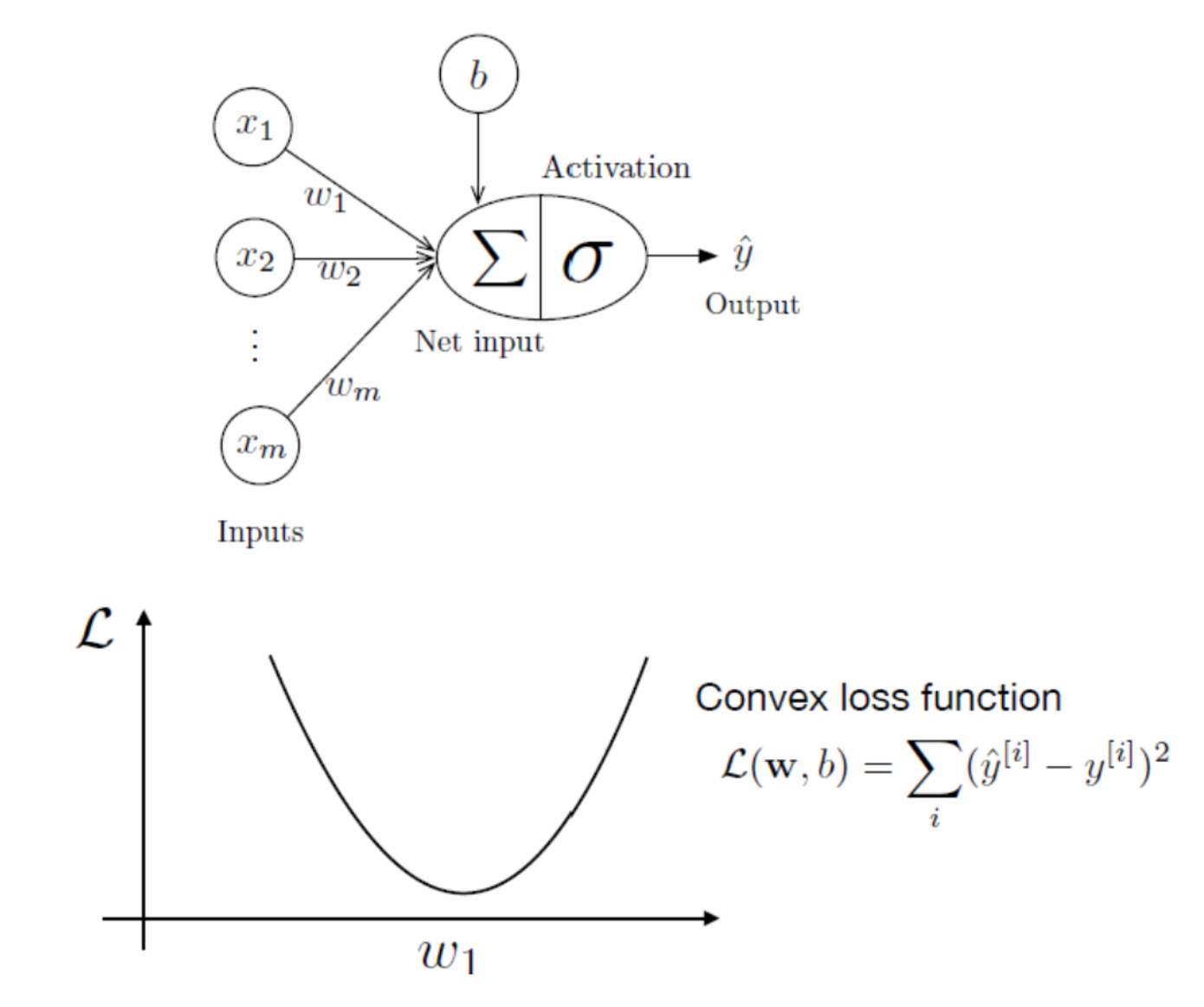
Gradient Descent
- Learning rate and steepness of the gradient determine how much we update
- Steps get smaller as you get toward the minimum
- Squared error gives convex loss function
- MSE loss is convex loss because we assume it’s the Sum Squared Error (SSE) or Mean Squared Error (MSE)
- Not every loss is convex
- Start with large learning rates and get smaller over time
Benefits of convexity:
- Especially for linear models, it is often not possible to achieve a zero loss even on the training data.
- Theoretical guarantee of convexity: reaching a unique minimizer efficiently.
- For general neural networks (due to nonlinear activation), no guarantee.
- If the learning rate is too large, we can overshoot, and if the learning rate is too small, convergence is very slow.
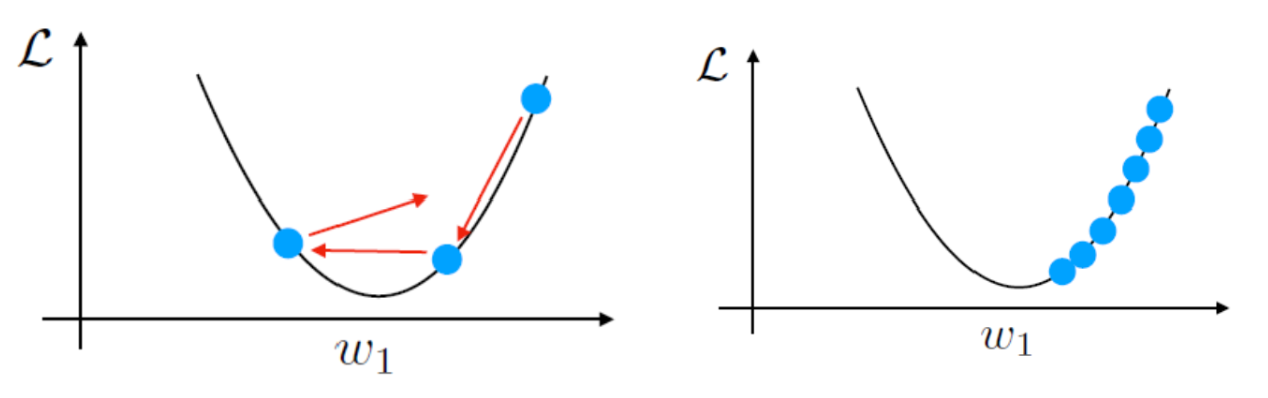
Returning to Previous Notes on Least-Squares Linear Regression
The update rule turns out to be this:
“On-line” mode (Perceptron learning rule)
- Initialize
- For every training epoch:
- For every $\langle x^{[i]}, y^{[i]} \rangle \in D$
Stochastic Gradient Descent (SGD)
- Initialize
- For every training epoch:
- For every $\langle x^{[i]}, y^{[i]} \rangle \in D$
- Where eta is the learning rate .
Linear Regression Loss Derivative
Sum of Squared Error (SSE) loss is also called squared loss.
- These equations show SSE.
- The activation function is the identity function in linear regression.
Alternative Linear Regression Loss Derivative
Mean Squared Error (MSE) often scales by factor ½ for convenience.
- These equations show MSE.
- The activation function is the identity function in linear regression.
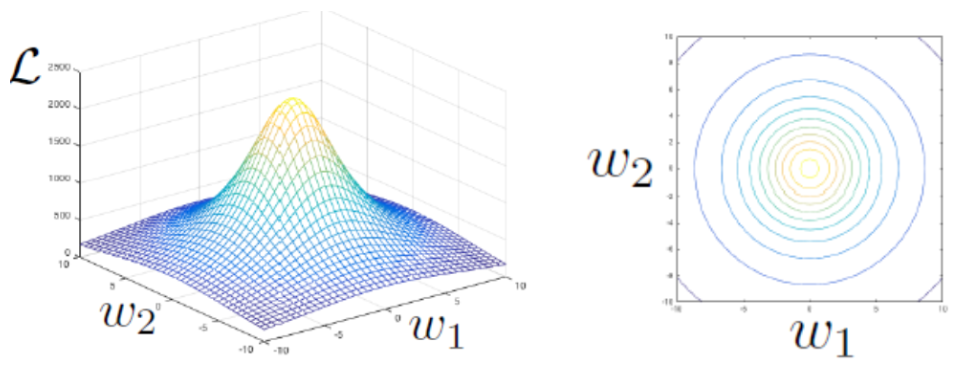
How to Think About Contour Plots
The following show the loss plot for two weights as a contour plot and flattened into a 2D space. As you can see, updates are perpendicular to contour lines.
Stochastic Gradient Descent as Surface Plot
Stochastic updates are a bit noisier because each minibatch is an approximation of the overall loss on the training set.
- These figures depict stochastic gradient descent.
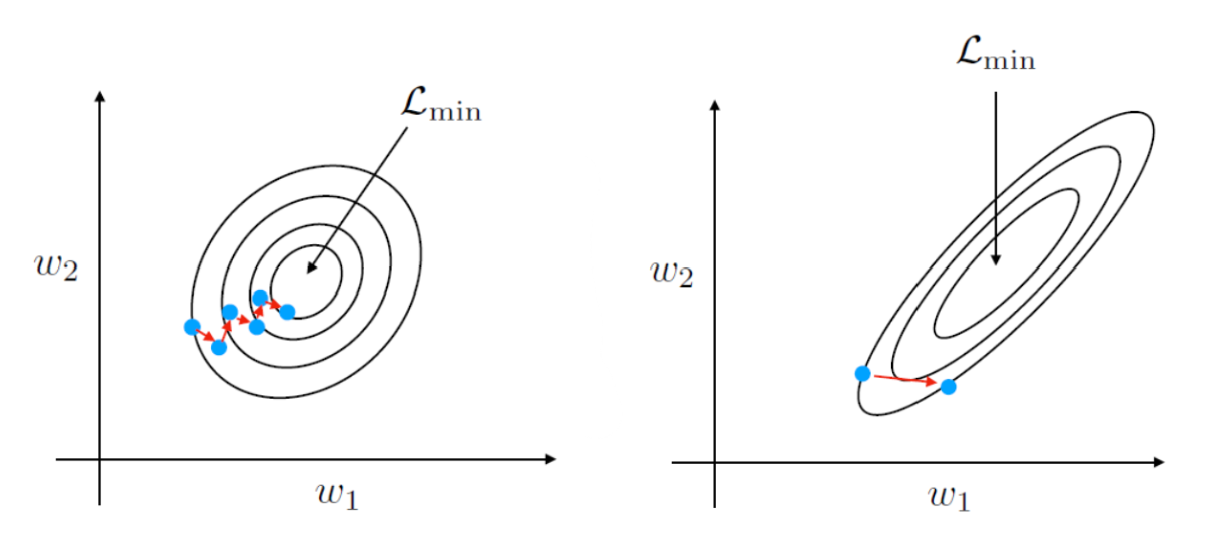
- If inputs are on very different scales, some weights will update more than others which will also harm convergence. This is why we always normalize inputs.
- Stochastic (on-line or minibatch) are noisier than batch (whole-training-set) gradient descent.
Analogy:
Imagine you are a scientist who develops a new pharmaceutical drug.
- To know its average effectiveness, you’d test it on all patients in the world (like batch GD).
- This is expensive and slow.
- Instead, you select a smaller group of patients (like minibatch).
- Your estimate won’t be perfect, but if the sample is large enough, it’s accurate enough to guide improvements.
7. Training and Adaptive Linear Neuron (Adaline)
(Least-Squares) Linear Regression
We want to speed up computations and memory when input data has large dimensions.
Assuming the bias is included in w, and the design matrix has an additional vector of 1’s.
ADALINE
Widrow and Hoff’s ADALINE (1960): A nicely differential neuron model.
- Stands for ADAptive LInear NEuron.