Lecture 23
Supervised Fine-tuning of LLMs
1. The Transition from Pre-training to Fine-tuning
The initial training of Generative Pre-trained Transformer (GPT) models is an unsupervised process designed to model the probability distribution of language, but it does not inherently equip the model for specific, goal-oriented tasks.
1.1 The Foundation: Unsupervised Pre-training Objective
Recall in Directed PGM for autoregressive model, the core training objective for GPT models is Maximum Likelihood Estimation (MLE). This probabilistic goal aims to maximize the log-likelihood of observed text sequences by learning to predict the next token given the preceding ones.
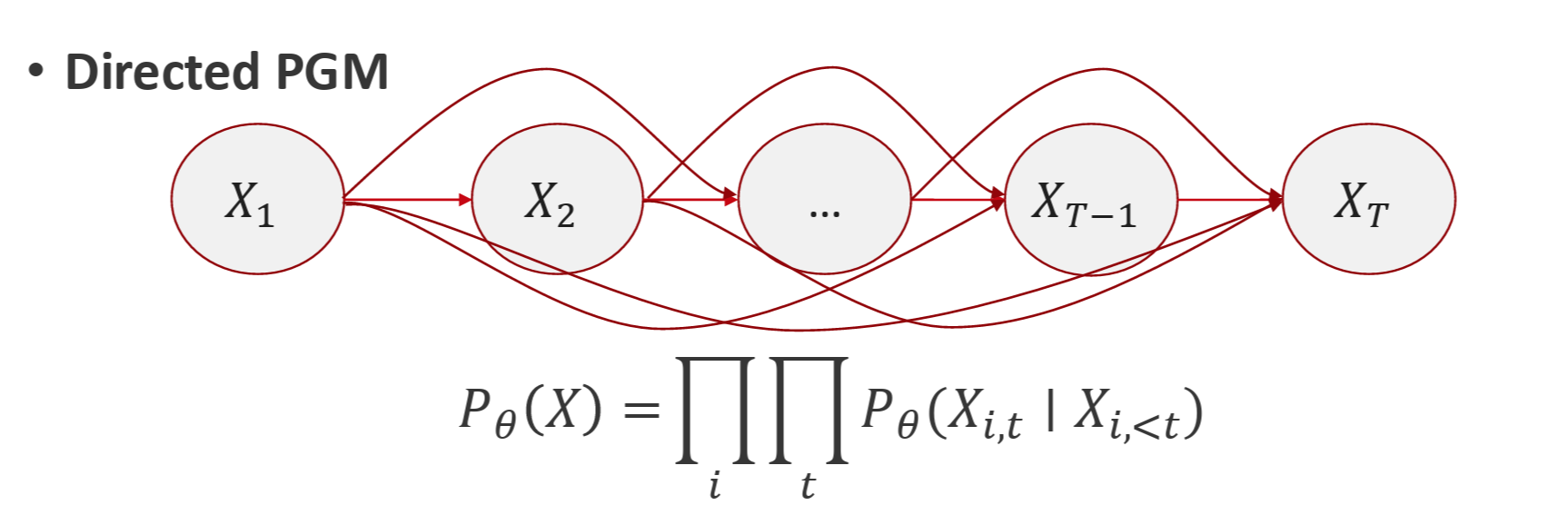
The objective is formally expressed as:
\[\max_{\theta} \sum_{i}\sum_{t} logP_{\theta}(X_{i,t}|X_{i,< t})\]This process effectively trains the model on the underlying structure and patterns of language (P(X)) found in the training data.
1.2 Inherent Limitations of Pre-training
While powerful for learning language, the MLE pre-training objective has significant limitations regarding the model’s practical usefulness. The source material explicitly identifies several missing components:
- No task goals: The model is not trained to accomplish a specific objective.
- No explicit reward: There is no mechanism to reinforce desirable outputs over undesirable ones.
- No utility: The concept of a “useful” or “helpful” response is not part of the training function.
- No semantics: The model learns statistical relationships, not a deep understanding of meaning.
These limitations necessitate a subsequent phase of fine-tuning to transform the base model into a useful and aligned assistant. The source underscores that in this entire process, “Dataset selection drives everything.”
2. Core Fine-Tuning Methodologies
To imbue pre-trained LLMs with utility, supervised and reinforcement learning techniques are applied to align model behavior with human intent and task requirements.
Why Fine-Tuning Is Needed
Although pre-training teaches the model to predict the next token and captures broad language patterns, the lecture emphasizes that MLE does not optimize for usefulness. As shown in the slides (pages 5–6), MLE provides:
- no task goals,
- no explicit reward,
- no notion of utility,
- no guarantee of helpful behavior.
This means a pre-trained model is good at modeling P(X) but not at following instructions, being safe, or producing task-oriented responses. Fine-tuning is therefore required to align the model with human objectives and teach it how to respond appropriately to prompts.
2.1 Supervised Fine-Tuning (SFT)
Supervised Fine-Tuning is a direct method to teach a language model how to respond appropriately to various types of prompts. The methodology is characterized as a form of “Behavior cloning,” where the model learns to imitate high-quality, human-generated responses from a curated dataset.
The impact of SFT is substantial. The development of InstructGPT demonstrated that a 1.3 billion parameter model, aligned via supervised fine-tuning and reinforcement learning from human feedback (RLHF), could outperform a much larger 175 billion parameter base GPT model on instruction-following tasks.
2.2 Reinforcement Learning from Feedback
Reinforcement Learning introduces an explicit reward signal, allowing the model to be optimized directly for desired outcomes.
Reward Model Training
For each training sample, we have:
- $(x$): the prompt
- $(y_w$): the preferred (winning) response
- $(y_l$): the less preferred (losing) response
The reward model $r_{\theta}(x, y)$ outputs scalar scores:
- $s_w = r_{\theta}(x, y_w)$
- $s_l = r_{\theta}(x, y_l)$
The training objective minimizes $-\log(\sigma(s_w - s_l))$.
Reinforcement Learning with Human Feedback (RLHF)
RLHF uses human preferences to train a reward model, which is then used to fine-tune the LLM. The success of this approach is critically dependent on the quality of the input data, with the source noting that “High-quality data is critical.” An open question in the field, attributed to John Schulman (2023), is whether human feedback effectively reduces model hallucinations.
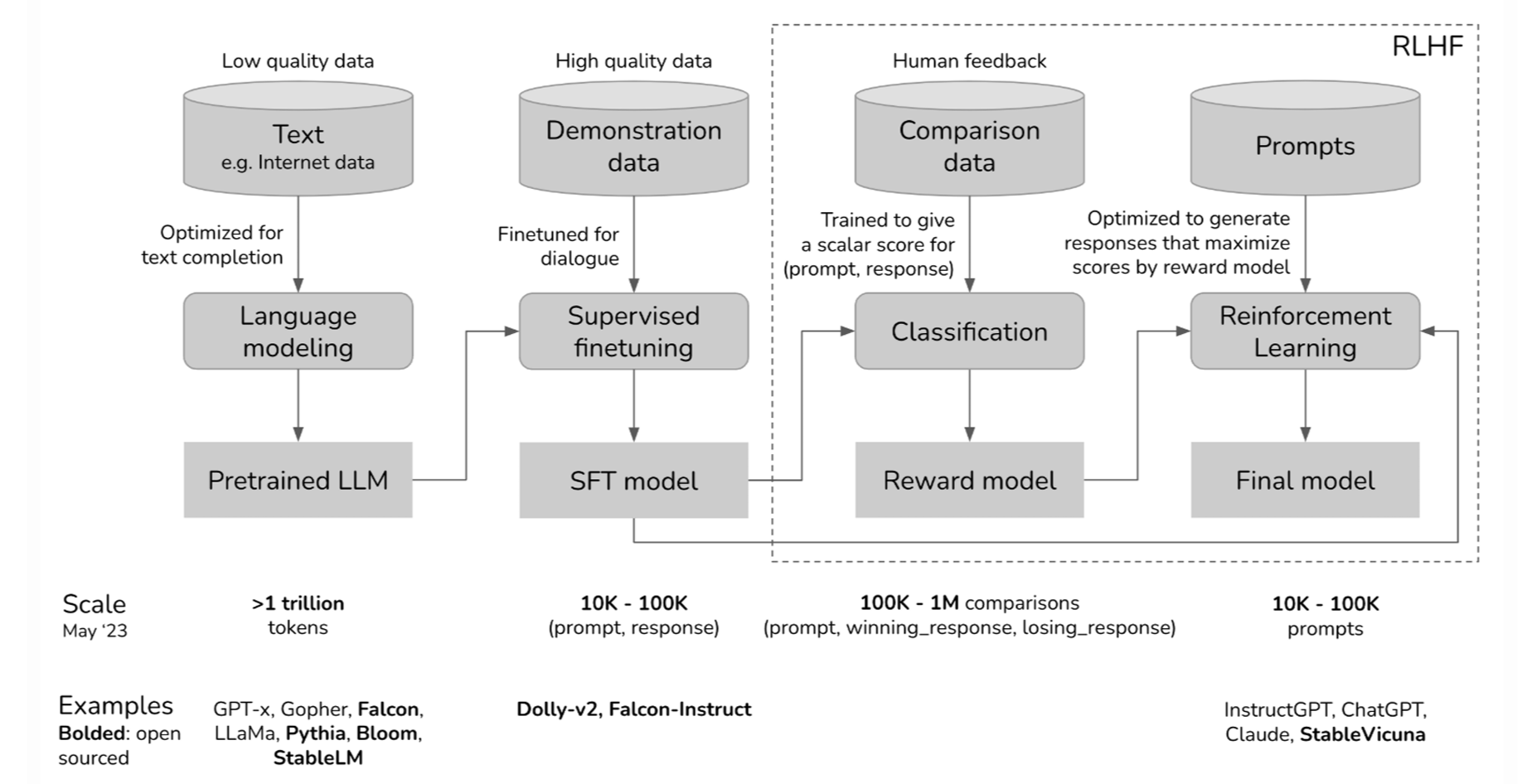
RLHF Pipeline
The slide presents the overall Reinforcement Learning from Human Feedback (RLHF) pipeline:
-
Pre-training
The base language model is trained on large-scale, low-quality text corpora to learn general language patterns. -
Supervised Fine-Tuning (SFT)
The model is fine-tuned on high-quality human demonstrations to align its behavior with desirable responses. -
Reward Model Training
Using comparison data, a reward model $r_{\theta}(x, y)$ is trained to assign higher scores to preferred responses. -
Reinforcement Learning (RL)
The SFT model is further optimized to maximize the learned reward from the reward model.
Models shown in the slide include: InstructGPT, ChatGPT, Claude, and StableVicuna.
Reinforcement Learning with Verifiable Rewards (RLVR)
RLVR is presented as a superior alternative to RLHF in domains where outputs can be objectively verified. Instead of relying on subjective human feedback, RLVR uses “verifiable truth” as its reward signal. This is particularly effective for tasks with clear success criteria, including:
- Code generation: Does the generated code run correctly?
- Math questions: Is the provided solution mathematically correct?
- Formatting-specifics: Does the output adhere to all specified formatting requirements?
2.3 Putting it together – Pipeline: From Base LM to Assistant
In practice, modern assistants are built in several stages:
-
Unsupervised pre-training
Train a large GPT-style model on raw text with MLE to learn general language and world knowledge. -
Supervised fine-tuning (SFT)
Collect prompt–response pairs and train the model to imitate high-quality answers (behavior cloning). This turns the base model into an “instruction-following” model. -
Reinforcement learning from feedback (RLHF or RLVR)
Use pairwise preference data or verifiable rewards to train a reward model and further optimize the policy with RL (e.g., PPO-style algorithms) to better match human preferences. -
Parameter-efficient and retrieval-based adaptation (LoRA / RAG)
For specific domains or users, we adapt the model either by:- Adding small trainable adapters (LoRA), or
- Plugging in external knowledge via retrieval (RAG), without retraining all billions of parameters.
SFT vs RLHF vs RLVR (high level)
| Method | Signal type | Pros | Cons / challenges |
|---|---|---|---|
| SFT | Supervised targets (y*) | Simple, stable, very data-efficient | Limited to what is in demonstrations |
| RLHF | Human preference rankings | Aligns with human judgments on many tasks | Expensive labels, subjective, may not reduce hallucinations |
| RLVR | Verifiable rewards (pass/fail) | Objective feedback, good for code/math | Only works where truth can be checked |
3. Parameter-Efficient Adaptation and Personalization
Adapting a massive LLM for every individual user or task is computationally prohibitive. Parameter-efficient methods have been developed to enable efficient and scalable personalization.
3.1 The Challenge of Personalization
The core challenge is that “Every user has their own preferences, history, and contexts.” To be truly effective, models must be able to adapt to these unique factors efficiently.
3.2 Low-Rank Adaptation (LoRA)
LoRA is a prominent parameter-efficient fine-tuning technique built on a key insight about model adaptation. The central hypothesis of LoRA is:
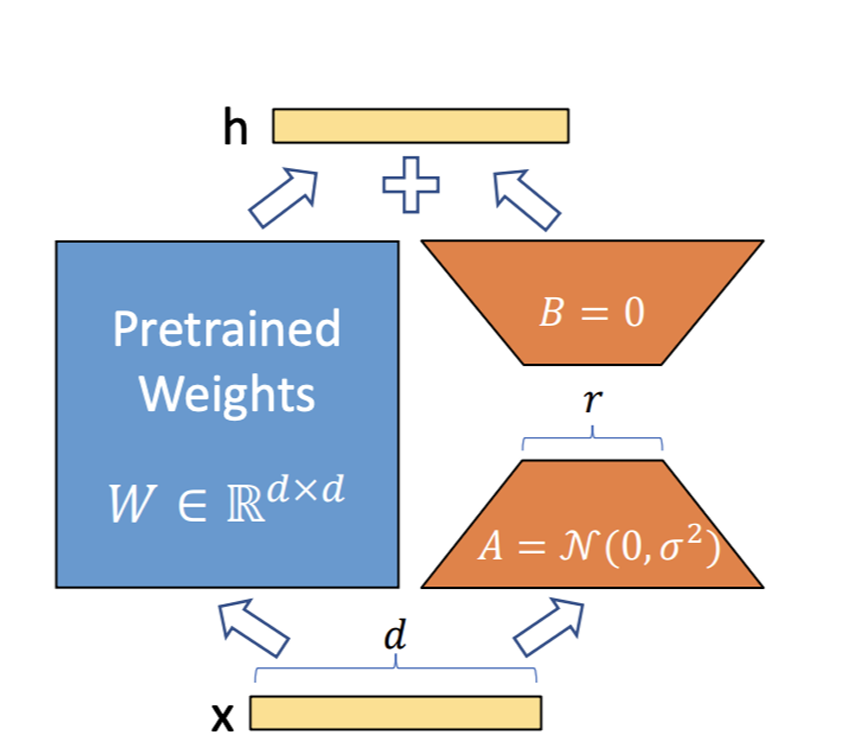
- The change in weights during model adaptation has a low “intrinsic rank.”
This means that instead of fine-tuning all the model’s billions of parameters, LoRA introduces a small number of trainable parameters that represent this low-rank change, drastically reducing the computational cost of adaptation.
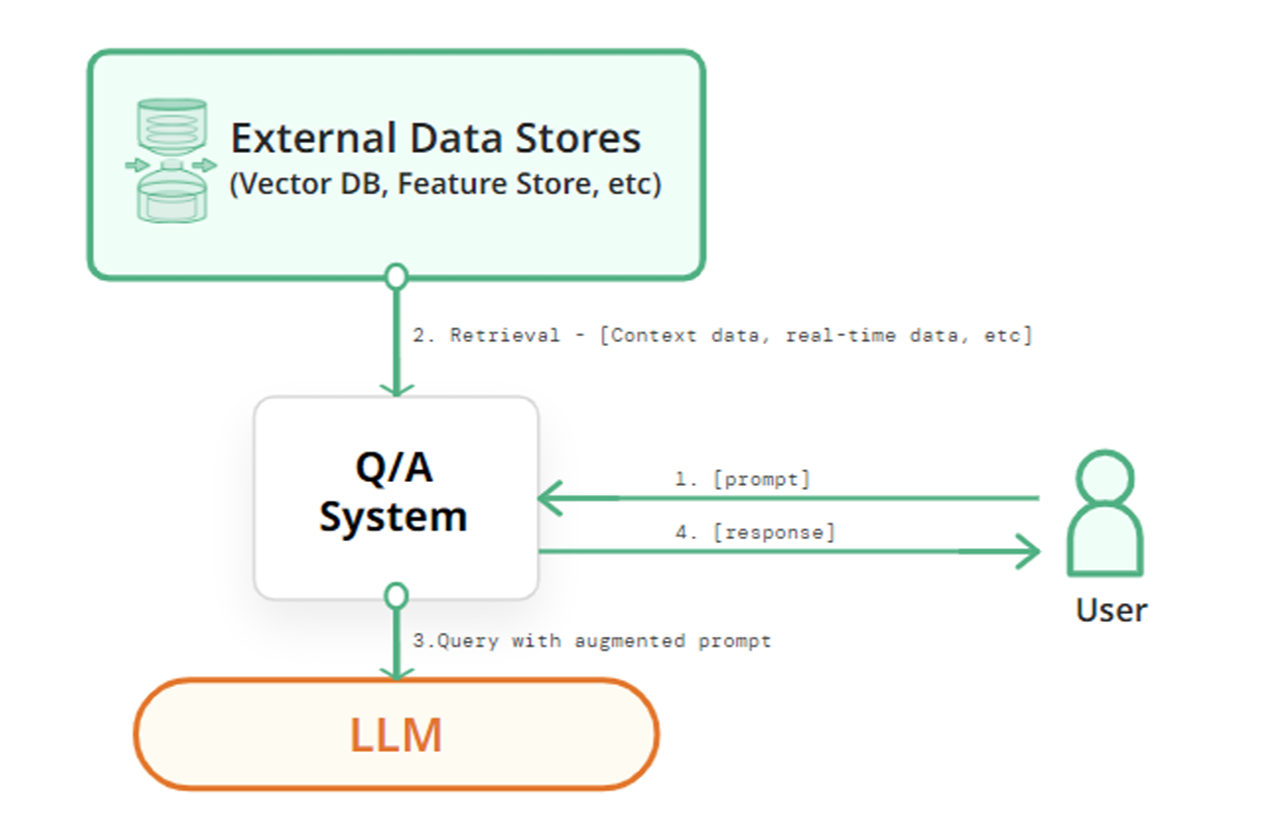
3.3 Retrieval-Augmented Generation (RAG)
RAG is another powerful technique for personalization and adaptation. Its core principle is that “Resource access enables personalization.” By allowing the model to retrieve information from an external knowledge base (which can include user-specific documents or data), RAG enhances the model’s responses with relevant, up-to-date, and context-aware information without requiring modifications to the model’s weights. The lecture materials also reference a specific advanced implementation, RAG of Interpretable Models (RAG-IM).
3.4 RAG of Interpretable Models (RAG-IM)
 RAG-IM (Retrieval-Augmented Generation of Interpretable Models) is an approach that constructs an interpretable predictive model by retrieving and combining a set of previously stored “archetype” linear models.
RAG-IM (Retrieval-Augmented Generation of Interpretable Models) is an approach that constructs an interpretable predictive model by retrieving and combining a set of previously stored “archetype” linear models.
Given a new task or input description, the system retrieves several relevant linear models from a model database. Each retrieved model contributes its own key, query, and value representations. These representations are processed using multi-head cross-attention, which determines how strongly each archetype model should influence the final output.
The attention-weighted combination of these models produces a new linear model that is specifically adapted to the current task while remaining fully interpretable. Because the final output is still a linear model, the prediction can be understood through its coefficients, preserving transparency and explainability.